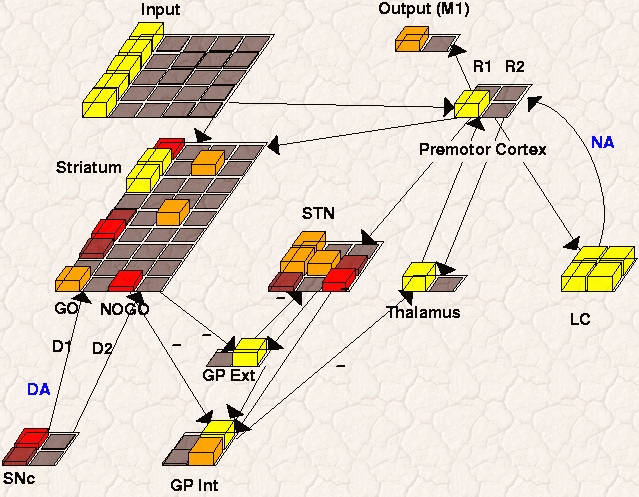
In this spurious trial, the BG initially facilitates two responses simultaneously, which is not a good thing when having to make choices! However, note that when these two responses are fully excited in premotor cortex, the additional response conflict drives a second STN Global NoGo signal; this leads to excitation of GPi and inhibition of the Thalamus. The lack of bottom-up support for both responses makes it easier for one to dominate and suppress the other (via lateral inhibition that is present in cortex), leading to the selection of just one response. At this point, the conflict in cortex goes down, and the STN Global NoGo signal turns off.
Incorporating Norepinephrine Function into the Model
This model explores the effects of norepinephrine (NE) in modulating
cortical response selection processes, as simulated by Aston-Jones,
Cohen and colleagues (see Aston-Jones & Cohen, 2005, Annual Review of
Neuroscience). Like DA cells in the SNc, firing states of NE-releasing
neurons in the locus coeruleus (LC) come in both tonic and phasic
modes. In electrophysiological recordings, LC cells release phasic NE
bursts during periods of focused attention, infrequent target
detection, and good task performance. This phasic NE burst is thought
to reflect the outcome of the response selection process and serves to
facilitate response execution. In contrast, poor performance is
accompanied by a high tonic, but low phasic, state of LC firing. The
authors simulated the effects of these LC modes on action selection
such that NE modulated the gain of the activation function in cortical
response units (Usher et al, 1999). They showed that phasic NE
release leads to ``sharper'' cortical representations and a tighter
distribution of reaction times, whereas the high tonic state was
associated with noisy activity and more RT variability, as observed in
their empirical work with monkeys. They further hypothesized that
increases in tonic NE during poor performance may be adaptive, in that
it may enable the representation of alternate competing cortical
actions during exploration of new behaviors.
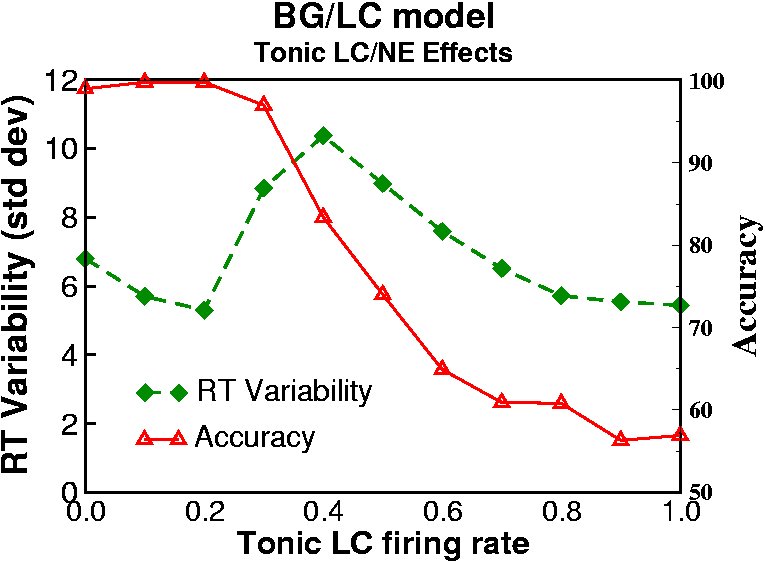
The below simulations explore how these effects play out within the context of the overall BG/DA action selection circuitry (see Frank, Scheres & Sherman (2007) and Frank, Santamaria, O'Reilly & Willcutt (2007) for simulation results, discussion, and implications for ADHD). We showed that (a) the tonic LC mode leads to increased representation of multiple cortical responses, (b) more reaction time variability, and (c) more erratic trial-to-trial response switching. In the phasic LC mode, tonic LC firing is low but punctate phasic bursts are elicited via top-down excitatory projections from premotor cortex. In this manner stimulus-evoked premotor activity (which arises from prior stimulus-response learning; see above) elicits a phasic LC burst, which in turn reciprocally modulates the gain of premotor units and facilitates the selection and execution of the desired response. These effects turn out to be especially critical in the presence of noisy cortical activity. To explore effects of LC/NE on noisy premotor activity, we delay the stimulus onset so that noisy activity is present in premotor cortex prior to processing of a task-relevant stimulus (as is likely the case in natural environments, but is typically not simulated).